Latest Post
Fine-tuning Pre-trained Models with Multi-tasks
Introduction
When a pre-trained model is fine-tuned for a single task (e.g., speech recognition), the model becomes
more adapted to that task. However, it loses much of what it learnt during pre-training — a phenomenon
commonly referred to as catastrophic forgetting.
Approach
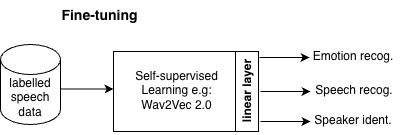
In this work, we fine-tune a self-supervised model — specifically Wav2Vec2.0-base — for
multiple downstream tasks simultaneously: speech recognition, emotion recognition,
and speaker identification.
We prepared a speech dataset where each audio sample carries three labels: text transcription, emotion,
and speaker identity. The dataset is sourced from the
Combined Dataset for Speech Emotion Recognition and includes:
- 14 emotion labels
- 33 character labels (for speech recognition)
- 373 speaker IDs
The pre-trained model is fine-tuned on approximately 22 hours of labeled speech data and
evaluated on 4 hours of held-out test data. For speech recognition, the
CTC objective is used, while for emotion recognition and speaker identification,
cross-entropy loss is applied.
Results
The table below summarizes our experimental setup and results using a 22/4/4 hour train/validation/test split.
| Fine-tune Data (hrs) |
Validation Data (hrs) |
Test Data (hrs) |
Speech Recognition (CER %) |
Emotion Recognition Accuracy |
Speaker Identification Accuracy |
| 22 |
4 |
4 |
24% |
60% |
78% |
Key Results:
We achieved a 24% Character Error Rate (CER) for speech recognition (without a language model),
60% accuracy in emotion recognition, and 78% accuracy in speaker identification.
Emotion recognition proved to be the most challenging task in this multi-task setup.
Remarks
Multi-task learning is more challenging than standalone single-task training, because individual tasks
tend to converge at different rates. A practical remedy is to assign different loss weights to each task,
allowing the training process to give more attention to harder tasks and improve overall performance.
Is Phoneme Recognition a Solved Problem?
Introduction
Phoneme is the basic unit of sound in each language that distinguishes one word from another.
Phoneme recognition refers to the task of converting speech signals into sequences of phonemic units.
This task is particularly important for applications such as pronunciation training, language learning,
and speech recognition.
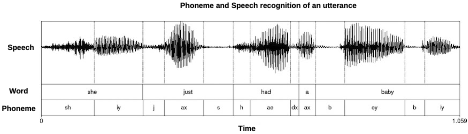
Figure below shows the phoneme and speech recognition of a sample audio using the
Praat Tool.
Data Preparation
Phoneme Recognition (PR) tasks require recorded utterances and corresponding phoneme sequences
prepared by linguistic experts. Sometimes timestamps are also provided for frame-level recognition.
TIMIT is one of the most widely used datasets for phoneme recognition and is available from the
Linguistic Data Consortium (LDC).
TIMIT contains phoneme and word-level timestamps and is widely used for benchmarking state-of-the-art systems.
How It Works
PR is a classification task, and various machine learning algorithms are used for training,
such as Multi-Layer Perceptrons (MLP), Convolutional Neural Networks (CNN), and Recurrent Neural Networks (RNN).
The performance of phoneme recognition systems continues to improve rapidly.
Recently, Self-Supervised Learning (SSL) models have demonstrated state-of-the-art performance for PR tasks.
SSL models are first trained using unlabeled speech data with a self-supervised objective.
This allows the model to learn abstract speech representations from raw audio.
A linear layer is then attached to the pretrained SSL model and fine-tuned for downstream tasks
such as phoneme recognition using limited labeled data.
Existing SSL models include:
- APC – predicts future frames from past speech frames.
- wav2vec 2.0 – uses contrastive predictive coding.
- HuBERT – predicts cluster labels generated from speech features.
- WavLM – combines masked prediction and speech denoising objectives.
In the next blog, we will compare the performance of these pretrained models on the TIMIT dataset.
Results
The following table summarizes selected phoneme recognition research papers from 2008–2020
evaluated on the TIMIT dataset using Phoneme Error Rate (PER).
| # |
Paper |
Year |
PER (%) |
| 1 |
Phoneme recognition in TIMIT with BLSTM-CTC |
2008 |
24.4 |
| 2 |
Speech recognition with deep recurrent neural networks |
2013 |
17.70 |
| 3 |
Attention-based recurrent neural networks |
2014 |
18.57 |
| 4 |
Convolutional deep maxout networks |
2014 |
17.76 |
| 5 |
Segmental recurrent neural networks |
2016 |
17.30 |
| 6 |
Recurrent DNN ensembles on TIMIT |
2018 |
14.69 |
| 7 |
wav2vec |
2019 |
14.70 |
| 8 |
VQ-wav2vec |
2019 |
11.64 |
| 9 |
wav2vec 2.0 |
2020 |
8.30 |
Observation:
The table shows that phoneme recognition performance has improved significantly,
reducing the PER from 24.4% to 8.30% using self-supervised learning approaches
such as wav2vec 2.0.
Discussion
Although current PR systems achieve impressive performance on English datasets such as TIMIT,
these models are often pretrained and fine-tuned on the same high-resource language.
An important open question is whether similar performance can be achieved for low-resource
and unseen languages.
Some important research questions include:
- Can SSL models generalize well to unseen low-resource languages?
- How much labeled data is needed for optimal phoneme recognition?
- How robust are these models to noisy real-world recordings?
- Can multilingual pretraining improve low-resource phoneme recognition?
Collecting high-quality training data for low-resource languages remains challenging because
recordings often contain environmental and background noise.